

2016-2022 All Rights Reserved.平安财经网.复制必究 联系QQ 备案号:
本站除标明“本站原创”外所有信息均转载自互联网 版权归原作者所有。
邮箱:toplearningteam#gmail.com (请将#换成@)
近日,备受各界关注的伯克利LLM排行榜再次更新了,Chat gpt-4在这份榜单中仍旧是排列在榜首的位置,Gpt-3.5仅仅排列在他的后面。由该团队发布的最新参数大模型Vicuna则冲到了第五名的位置,以330亿参数成为了众多开源模型中最好的成绩,领先微软华人团队开发的300亿参数模型。这一次排行榜不仅加入了更多的新模型,而且还加入了两个全新的评价标准。
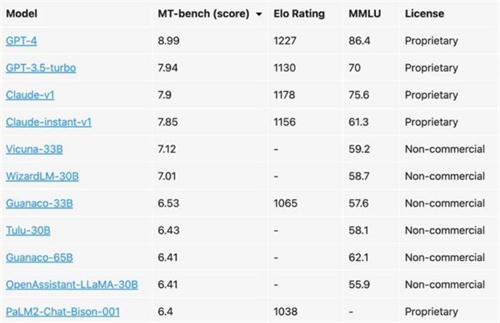
从各项数据中来看,GPT-3.5、Claude-v1和Claude-instant-v1这几个模型的排行简直是很难分出高低,而且在得分上咬的十分紧,甚至在某些得分领域,都有着互相反超的趋势,和这些专有模型相比。一些开源模型则是有着比较明显的差距,比如谷歌的开源模型就落后众多开源模型,在评估人类偏好的时候,传统的基准测试通常是在封闭式的问题中完成测试,并且会提供一些简洁的输出作为评价依据。

这家来自UC伯克利的团队在这一次的排行中增加了一项新的基准测试,竞技场的具体评价机制是基于收到的42000个匿名投票,并且采用elo评价机制完成评分,这一方法已经经过了验证,是一个精心测试的基准测试功能。其中是包含了80个高质量的多轮问题,通过这些问题,能够评估模型在多轮对话中的遵循能力与对话流程能力,其中是包含了一些常见的日常使用场景,还添加了更多富有挑战性的指令。

团队在最新的论文中还公布了一项系统研究,该研究的结果显示,gpt-4这样强大的评判者,在一致性上是超过了80%。这种一致性的水平已经能够和两个人类评判者中的一致性相媲美,基于chat gpt的评分能够更好的去对其他的模型做出排名,而且可以和人类偏好做出更好的匹配。如果使用得当的话,这种评论模型能够作为人类偏好发展的拓展解释。






2016-2022 All Rights Reserved.平安财经网.复制必究 联系QQ 备案号:
本站除标明“本站原创”外所有信息均转载自互联网 版权归原作者所有。
邮箱:toplearningteam#gmail.com (请将#换成@)