

2016-2022 All Rights Reserved.平安财经网.复制必究 联系QQ 备案号:
本站除标明“本站原创”外所有信息均转载自互联网 版权归原作者所有。
邮箱:toplearningteam#gmail.com (请将#换成@)
根据泄露的谷歌内部文件中可以看到,有一位内部研究员表示,虽然谷歌和open AI这两家公司在AI领域互相追赶,很可能最终都没办法取得胜利,开源这一力量也在悄然的崛起。
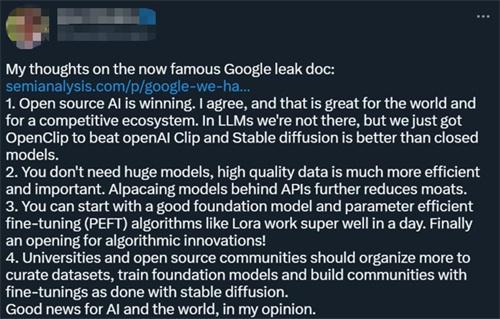
围绕着 Meta以及语言模型等重多大开源模型,整个社区当中迅速将开源和语言大模型能力有着相似类型的模型,更新迭代方面有着更快的速度,拥有更强的定制性能且私密性更好,当并不受到限制的免费的替代品在品质方面相当的时候,便不会为有限制的模型而付费。
对于全世界来说,开源的胜利是一件好事,对于构建整个竞争生态系统来说也是较好的事情,在大型的语言模型领域还没有正式能够做到这一点。不需要较为庞大的模型,高质量的数据会更加有效果。
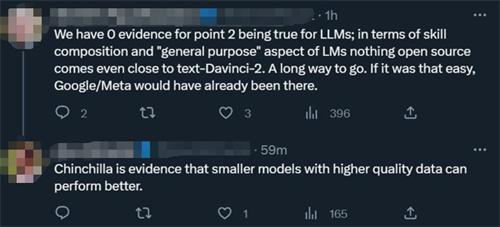
但也不是所有的研究者对于文章当中的观点都表示赞同,对开源的模型是否能够和open AI创建出来大模型的能力以及在各种类型通用性有一定的质疑,对于学术界来说,开源这一项力量能够不断的崛起这件事情还是很好的,即使没有拥有1000块的GPU研究者而已,依据开源的模型有事情可以进行。
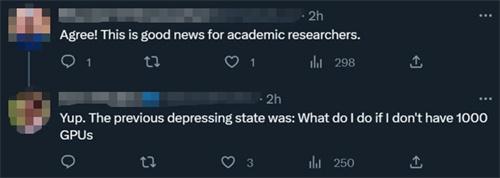
3月初meta的这一模型在公众视野泄露了,开源的社区就真正获得了第1个基础类且有用的模型,虽然并没有对话或指令方面的调整,但开源社区立刻将大型语言模型这些重要性牢牢把握,仅仅只隔了几天在发展中也能看到不断的创新进展,在一个月之后量化质量微调,质量改进等众多变体纷纷出现,大多数在彼此基础上作出构建。






2016-2022 All Rights Reserved.平安财经网.复制必究 联系QQ 备案号:
本站除标明“本站原创”外所有信息均转载自互联网 版权归原作者所有。
邮箱:toplearningteam#gmail.com (请将#换成@)